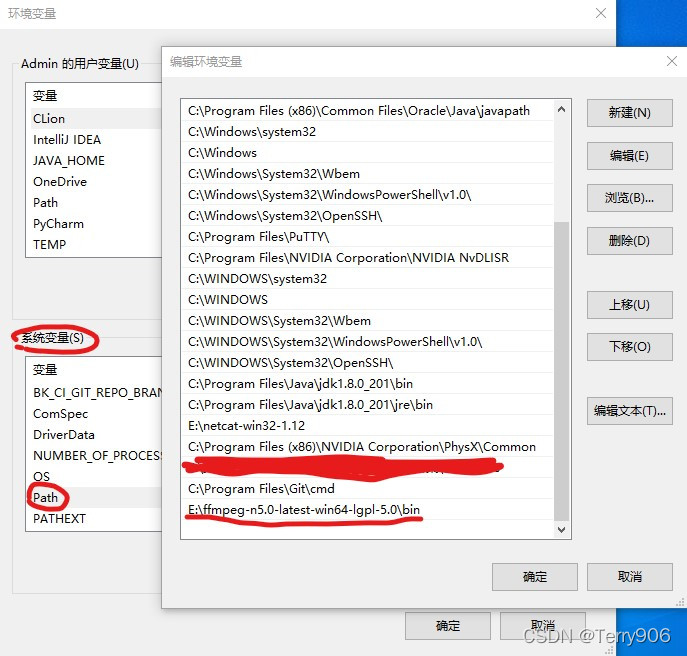
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
import requests
import re
from concurrent.futures import ThreadPoolExecutor
from ffmpy3 import FFmpeg
def get_first_m3u8(url,headers):
resp = requests.get(url,headers)
obj = re.compile(r'"link_pre":"","url":"(?P<first_m3u8>.*?)","url_next"',re.S)
m3u8_url = obj.finditer(resp.text)
for it in m3u8_url:
first_m3u8 = it.group("first_m3u8").replace("\\","")
print(first_m3u8)
return first_m3u8
def download_first_m3u8(url,name,headers):
resp = requests.get(url,headers)
with open(name, "w", encoding="utf-8") as f1:
f1.write(resp.text)
with open(name,"r") as f2:
for line in f2:
if line.startswith("#"):
continue
else:
line.strip()
print(line)
return line
def get_second_m3u8(url,headers):
first_m3u8 = get_first_m3u8(url,headers)
line = download_first_m3u8(first_m3u8,"爬到的视频/first_m3u8.txt",headers)
second_m3u8 = first_m3u8.split("/20220112")[0] + line
print(second_m3u8)
return second_m3u8
def ffmpeg_path(inputs_path, outputs_path):
'''
:param inputs_path: 输入的文件传入字典格式{文件:操作}
:param outputs_path: 输出的文件传入字典格式{文件:操作}
:return:
'''
a = FFmpeg(
inputs={inputs_path: None},
outputs={outputs_path: '-c copy',
}
)
print(a.cmd)
a.run()
if __name__ == '__main__':
url = "https://www.yunbtv.net/vodplay/ITgou-1-1.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
"Referer": "https://www.yunbtv.net/"
}
second_m3u8 = get_second_m3u8(url,headers)
with ThreadPoolExecutor(50) as t:
t.submit(ffmpeg_path,second_m3u8,"爬到的视频/IT狗第一集.mp4")
|